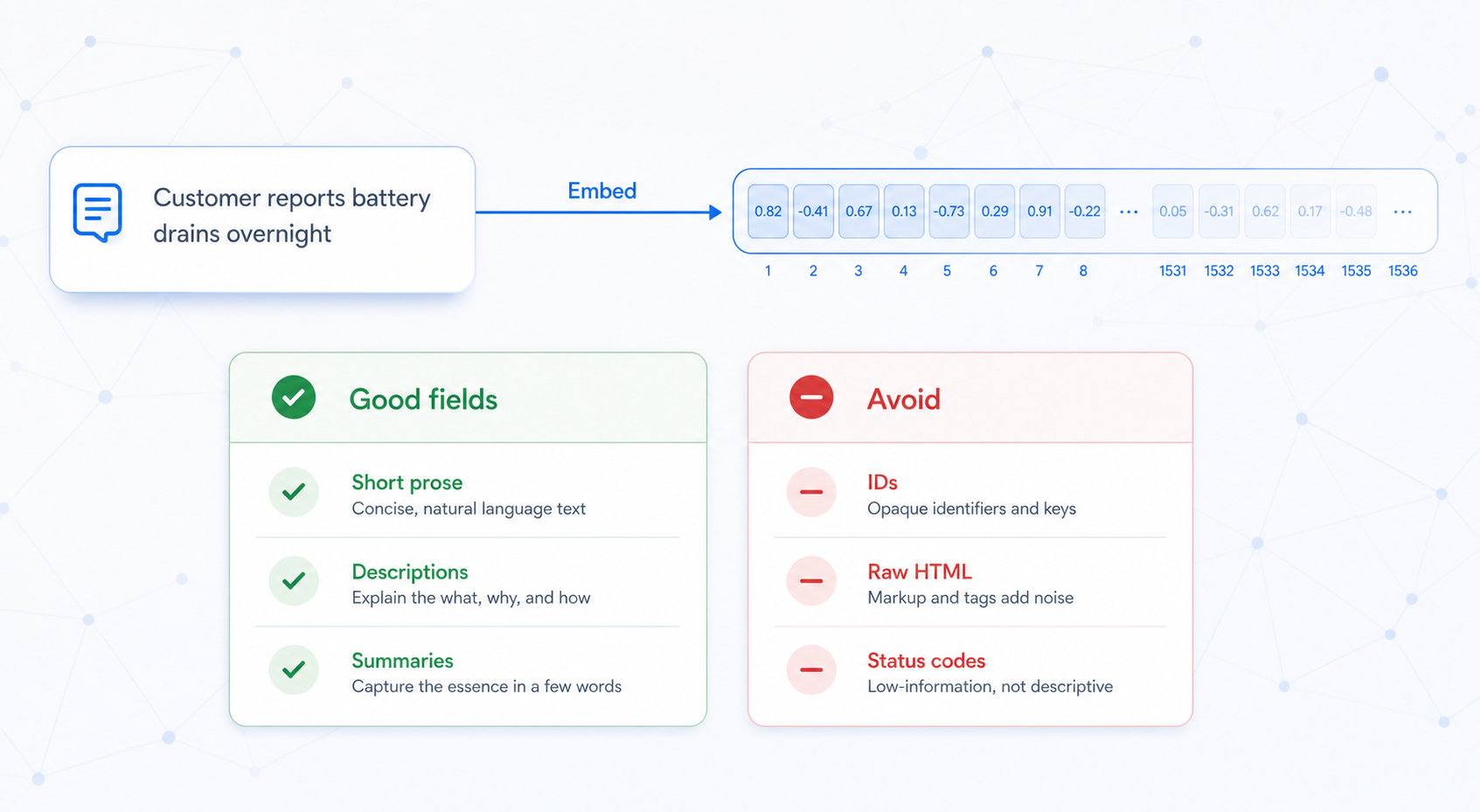
Embeddings
An embedding is a dense numeric vector that captures the meaning of a piece of text. Curiosity uses them to power vector search and similarity features.
What to embed:
| Embed | Skip |
|---|---|
| Ticket bodies, case descriptions | Short IDs and status codes |
| Long article or document text | Boilerplate and repeated headers |
| Summaries and transcripts | Raw HTML or markdown noise |
| Free-form comments | Fields shorter than 5 words |
Chunking: long fields should be split into overlapping chunks before embedding. A single vector for a 10-page document loses too much detail.
- Chunk size: 200–800 tokens (start at 512)
- Overlap: 10–20% (e.g. 64 tokens for 512-size chunks)
- Boundary: prefer paragraph breaks over hard token cuts
Enable in Settings → Search → Indexes: toggle the vector index for a field, set chunk size and overlap. A background job backfills embeddings for existing nodes.