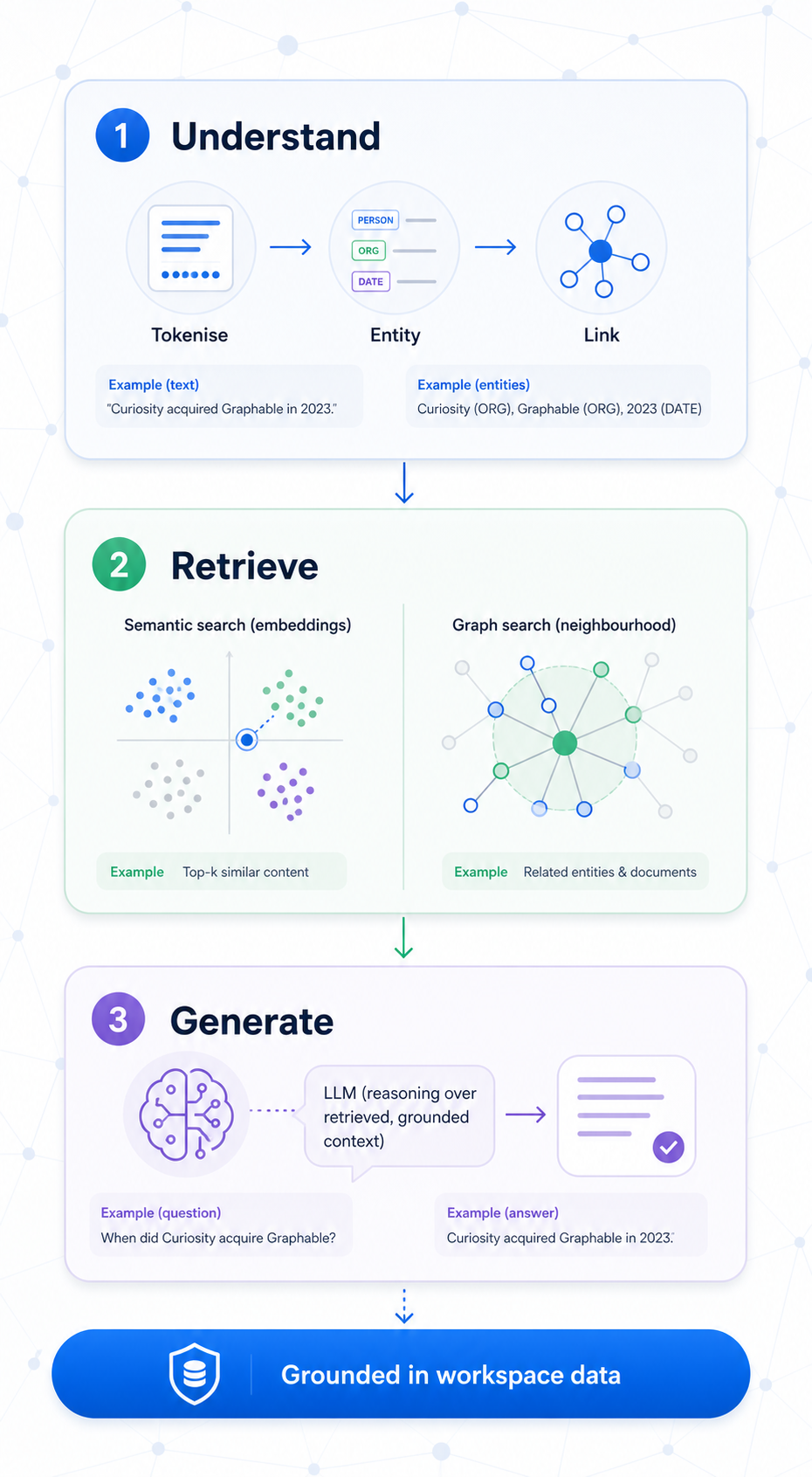
AI in Curiosity
Three distinct capabilities. They build on each other.
| Layer | What it does | Examples |
|---|---|---|
| Understand | NLP pipelines — extract entities, detect language, embed | Entity spotters, embeddings |
| Retrieve | Semantic similarity — find relevant context | Similar tickets, RAG candidates |
| Generate | LLM — synthesise a response from retrieved context | Q&A, summarisation, classification |
The key principle: LLMs are always grounded.
User question
→ retrieve relevant nodes from graph + search
→ send context to LLM
→ LLM synthesises answer + citations
The LLM never answers from training data alone. It only works with what the workspace retrieved on the user's behalf — and only what that user can see.
What NOT to use an LLM for:
- Permission checks — use endpoints
- Deterministic business rules — use endpoints
- Data mutations requiring strict correctness — use endpoints