What is similarity search?
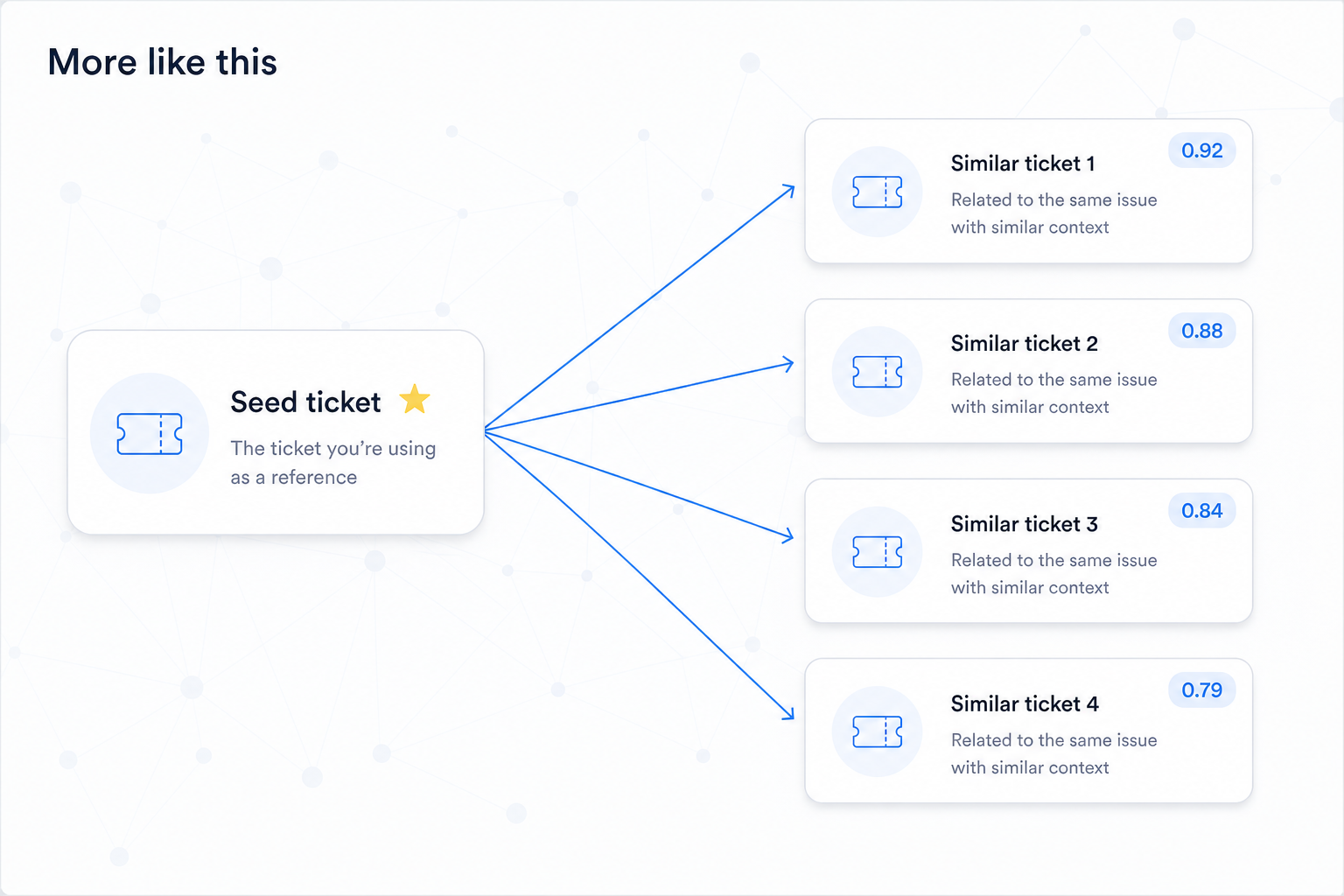
Similarity search finds items that are semantically close to a seed — a query, a document, or another node. It's the engine behind "more like this", related items, and candidate generation for AI.
Two building blocks:
Sentence embeddings — a dense vector representation of a text field, stored per node. Two nodes with similar vectors are semantically similar.
The similarity engine — a composable ranking system that combines multiple signals (embeddings, graph traversals, external lookups) into a single ranked list.
When to use it:
| Use case | What you build |
|---|---|
| "More like this" button | Seed node → similar nodes by embedding |
| Related items panel | Seed node → neighbours by graph, then re-rank by embedding |
| Duplicate detection | Pairs with similarity > threshold |
| RAG candidate generation | Query text → top-k similar chunks as LLM context |
Similarity search is a complement to keyword/hybrid search — not a replacement. Use them together.