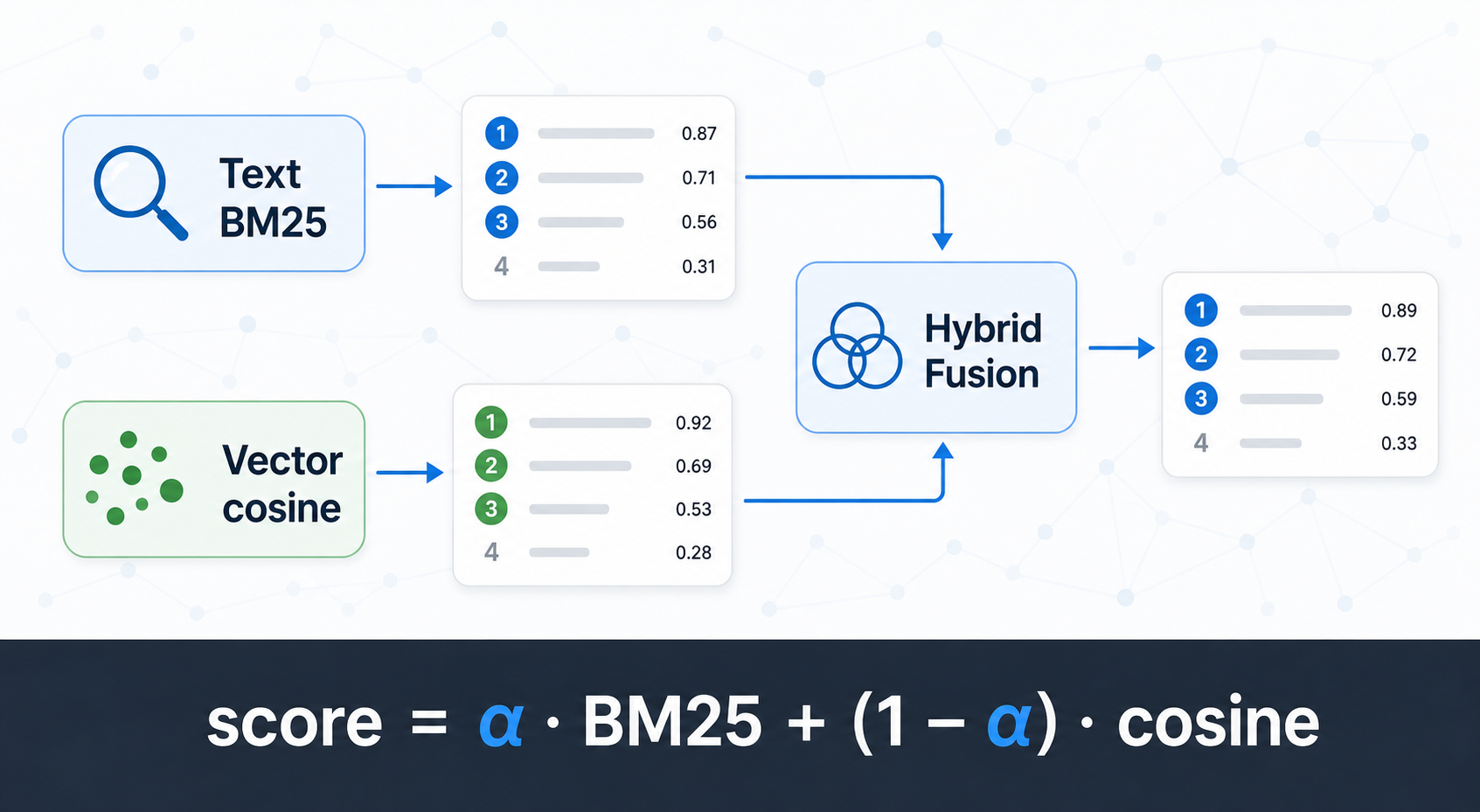
Hybrid search
Text and vector retrievers run in parallel. Their scores are normalised and blended.
How it works:
Text branch (BM25) → normalise to [0, 1] ─┐
├→ final score = α·text + (1-α)·vector → rank
Vector branch (cosine) → normalise to [0, 1] ─┘
The two result lists are unioned by node UID before blending. A node that only appears in one branch still gets a score (the other branch contributes 0).
Tuning the blend (α):
| Corpus type | Recommended α |
|---|---|
| Heavy on identifiers and codes | 0.6–0.7 |
| Long-form narrative, Q&A | 0.4–0.5 |
| Balanced (default) | 0.5 |
Set α in Admin → Search Settings or per-request in SearchRequest.VectorSearchWeight.
Evaluate before changing α: collect 80+ golden queries with expected results, sweep α ∈ {0, 0.25, 0.5, 0.75, 1}, pick the value with the best precision@3 and NDCG@10.