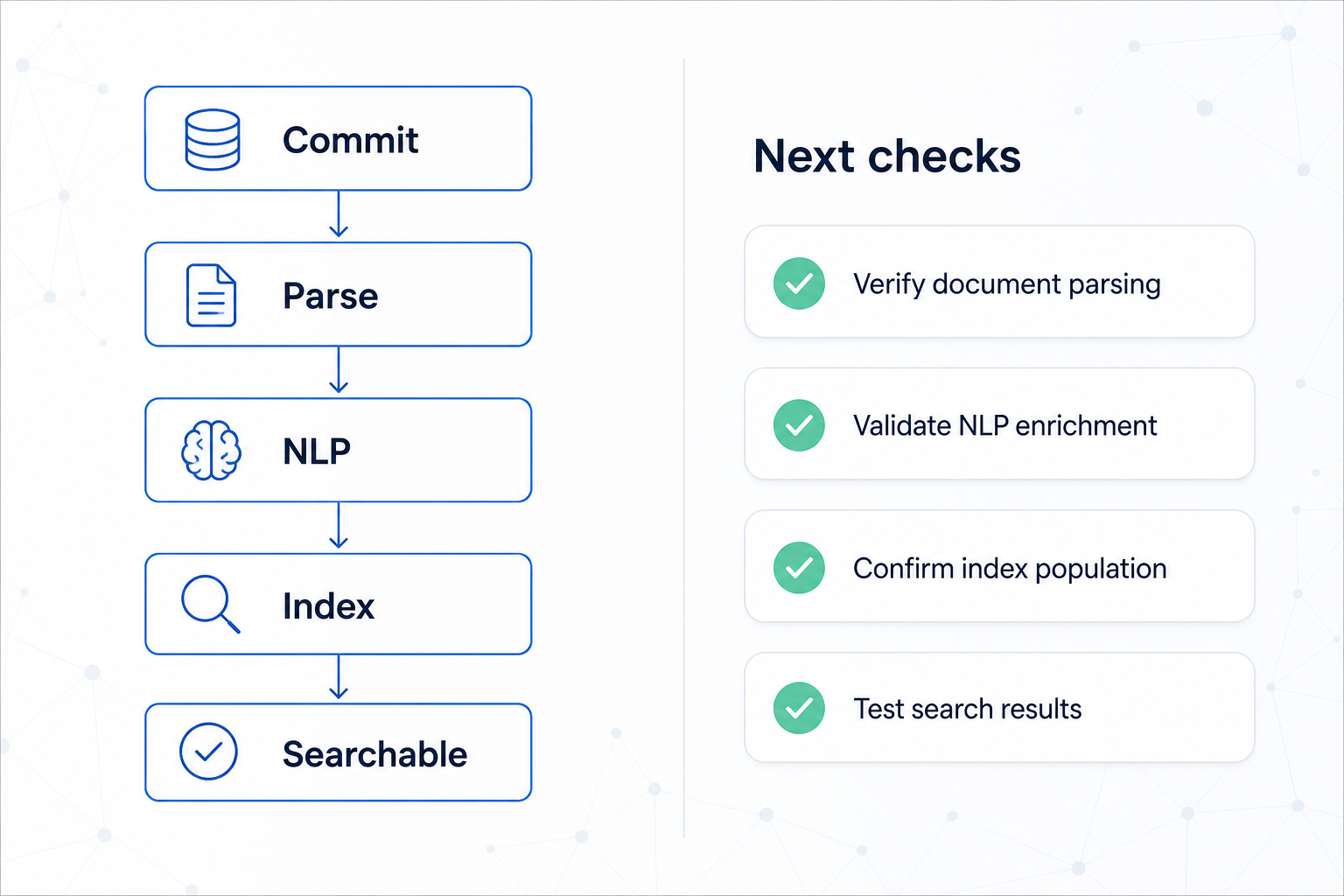
What happens after you commit
The workspace runs background jobs automatically — you don't trigger any of this.
Commit
↓ Parsers extract plain text from PDF, Office, HTML …
↓ NLP pipelines tokenise · detect language · extract entities · generate embeddings
↓ Indexers populate text and vector search indexes
↓
Searchable
What you can tune (once the data is in):
- Which fields are indexed for text search
- Which fields get vector embeddings and with what chunking
- Which entity types the NLP extractor links back to graph nodes (e.g. product names →
Productnodes)
These are workspace-level settings — covered in the NLP and Search presentations.
Before going to production:
- Running the connector twice produces identical node and edge counts
- Cursor advances only after a successful commit
- Every access-controlled node has
RestrictAccess*set - An end-user test account sees the data it should — and only that data
- Deletes from source eventually propagate to the graph
- Credentials come from environment variables, not source code
What to read next:
| NLP enrichment | Turn extracted entities into graph nodes |
| Search | Query the text and vector indexes |
| Data Connector SDK | Full SDK reference |
| Schema design | Detailed schema guidance |
| Ingestion pipelines | Orchestrating connectors at scale |