AI Models
Curiosity Workspace uses AI models in three common ways:
- Understanding: NLP pipelines that extract structure from text (entities, signals, links).
- Retrieval: embeddings used for semantic similarity (vector search) and re-ranking.
- Generation: LLMs used for synthesis, assistance, and workflow automation.
The important architectural point: AI features are most reliable when they are grounded in your workspace data via graph + search retrieval.
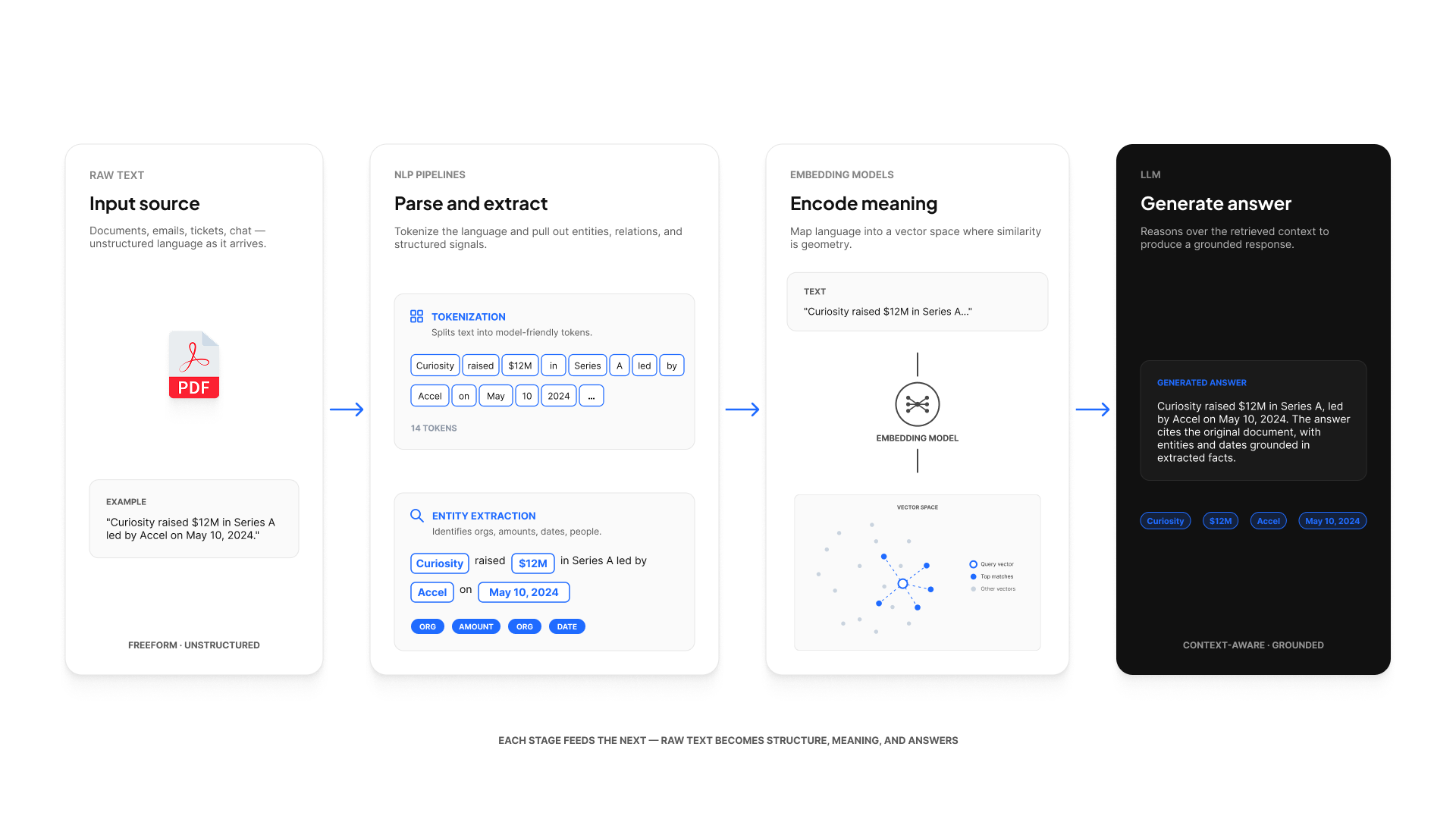
Embedding models (semantic similarity)
Embedding models map text (and sometimes other modalities) into vectors. In Curiosity Workspace, embeddings are used for:
- vector search (find semantically similar items)
- clustering and similarity (group related items)
- candidate generation for AI-assisted workflows
Design considerations:
- choose which fields get embeddings (usually long, descriptive text)
- enable chunking when fields exceed model context limits
- decide whether vector search is a primary retrieval method or a supplement to text search
See NLP → Embeddings and Search → Vector Search.
NLP pipelines (extraction + enrichment)
NLP pipelines transform raw text into structured outputs, such as:
- extracted entities (people, products, IDs)
- normalized tokens and language-specific parsing
- optional entity linking into your graph
This enables:
- better filters (entities become facets)
- better graph navigation (mentions → resolved entities)
- better retrieval grounding for LLMs
See NLP → Overview and NLP → Entity Extraction.
LLMs (generation + orchestration)
LLMs are typically used to:
- answer questions using retrieved context
- summarize, classify, or extract structured outputs
- drive multi-step workflows (tools, endpoints, actions)
Recommended patterns:
- retrieval first: fetch relevant nodes/documents before prompting
- tooling: move business logic into endpoints/tasks rather than relying on prompts alone
- auditability: store inputs/outputs where needed (policy dependent)
See AI & LLMs → Overview and AI & LLMs → Prompting Patterns.
Safety and governance (conceptual)
Production AI typically needs:
- permission-aware retrieval
- logging/auditing for sensitive workflows
- strict separation of admin-only capabilities
See Administration → Security.
Next steps
- Configure AI/LLM behavior: AI & LLMs → LLM Configuration
- Design semantic retrieval: Search → Hybrid Search