Pipelines
A pipeline is a sequence of NLP steps applied to a (node type, field) pair.
Default stages:
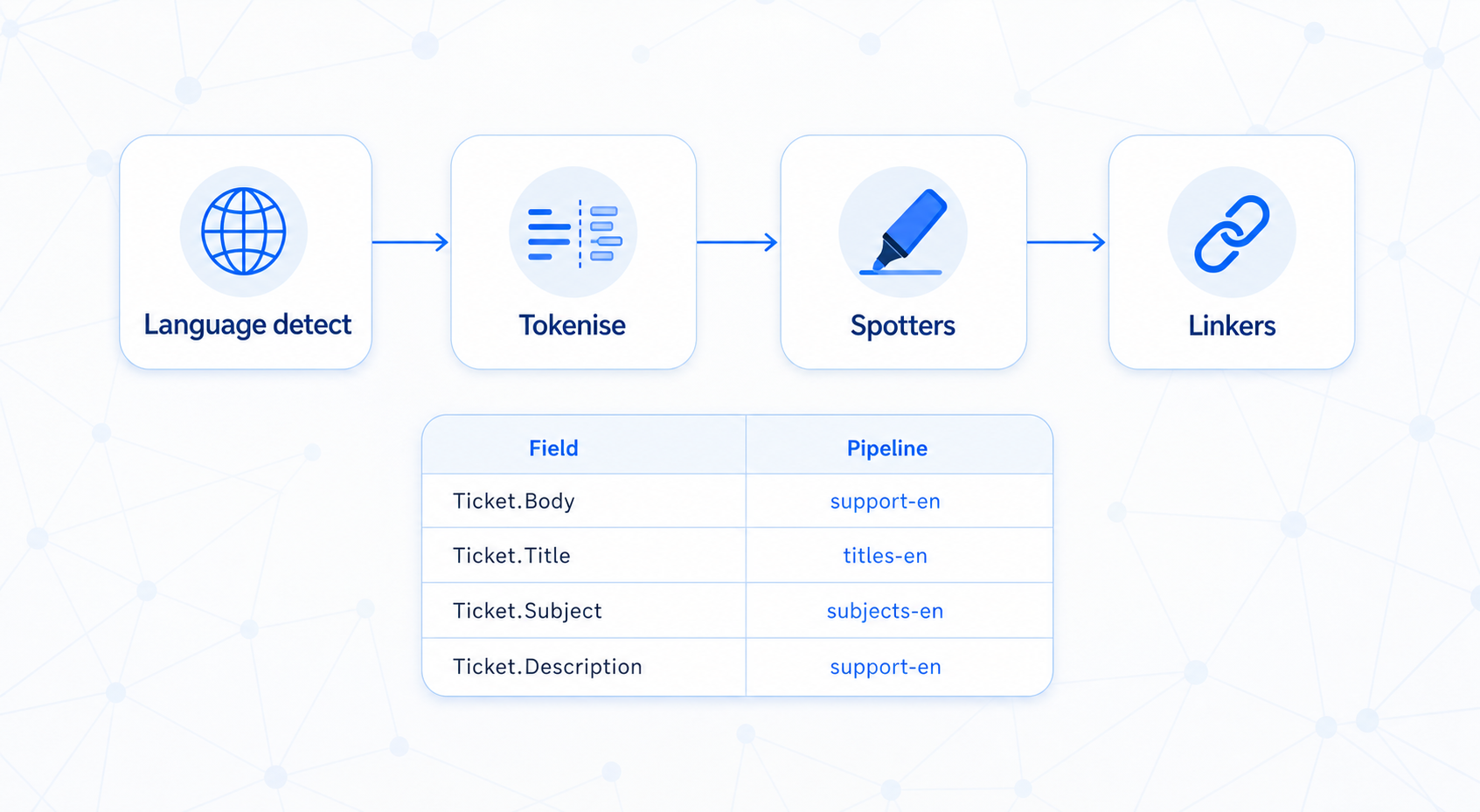
Language detection → Tokenisation → Normalization → Spotters → Linkers
- Language detection routes mixed-language content to the right models
- Spotters find entity mentions (dictionary, pattern, or ML-based)
- Linkers connect mentions to existing graph nodes
Assigning a pipeline:
In Settings → NLP → Pipelines, pick a pipeline and assign it to one or more (node type, field) combinations. Every value in that field — past and future — flows through the pipeline.
Three built-in modes:
- Data Parsing — production, runs on all committed content
- Conversational — optimised for short chat/query text
- Custom — full control over stages and models
Multilingual content: create one pipeline per language; the language detector routes each sentence automatically. Mixed-language fields split at sentence boundaries.